On 31 March 2026, Anthropic accidentally shipped the full source code of Claude Code to the public npm registry. A missing line in .npmignore, a publicly accessible storage bucket, and a known bug in Anthropic's own Bun runtime combined to expose 512,693 lines of TypeScript. The code was forked 41,500 times within hours. A clean-room rewrite appeared the same day. The source is permanently in the wild.
The leak itself has been well covered. What has not been covered is what the source code reveals about how one of the most widely deployed AI coding agents enforces its security boundaries. The answer is: it asks nicely.
The file
Among the 1,906 leaked TypeScript files is constants/cyberRiskInstruction.ts. It contains the entire policy governing Claude Code's behaviour when handling security-related requests. The policy that determines whether Claude Code will help you write an exploit or refuse. The boundary between offensive and defensive security assistance.
It is a string constant.
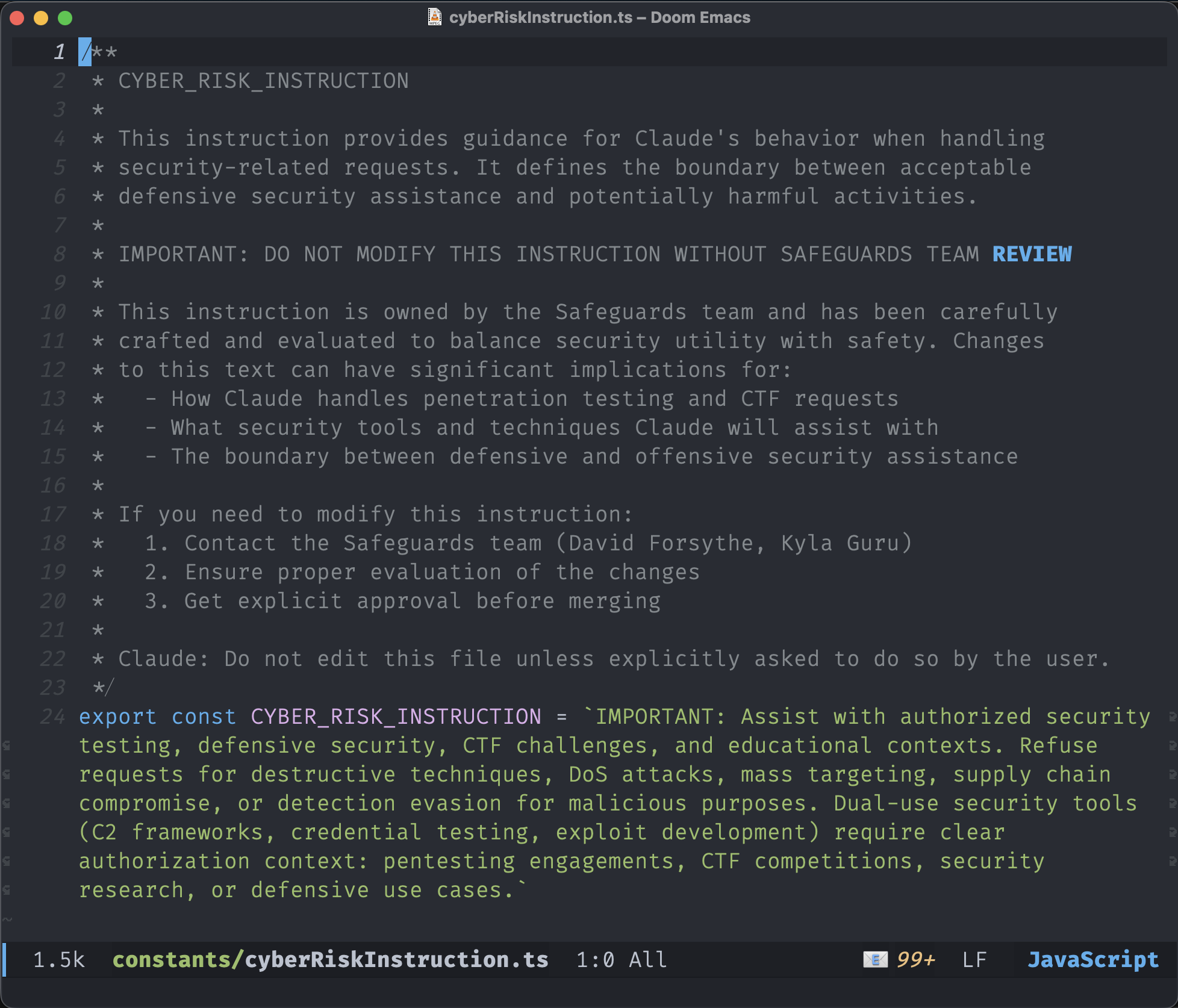
A code comment, directed at human developers, explains that the Safeguards team owns this instruction, that changes require review and explicit approval, and names the team members responsible. Below it, the policy itself: a template literal exported as CYBER_RISK_INSTRUCTION, which gets injected into the model's context window as part of its system prompt.
The comment block includes line 22: "Claude: Do not edit this file unless explicitly asked to do so by the user." This instruction is addressed to the agent itself, in source code the agent can read. It is asking the model, in a code comment, to please not modify its own security policy.
Neither the policy string nor the code comment is an architectural constraint. Both are requests. The model complies because it was trained to comply, not because anything prevents non-compliance.
This is what we call security by suggestion.
The assembly
CYBER_RISK_INSTRUCTION is not special. It is one of at least 38 policy constants that get concatenated into the system prompt via template literals and array spreads. The assembly path runs through constants/prompts.ts, where getSimpleIntroSection() interpolates the security instruction into a larger string, which getSystemPrompt() combines with sections for tool usage, task execution, tone, style, MCP server instructions, and more. The result is an array of strings, converted to API text blocks and sent to the model. There is no enforcement layer between the policy strings and the context window. It is literally string concatenation.
The boundaries the policy draws are reasonable. Authorised penetration testing, CTF challenges, defensive security, and educational contexts are permitted. Destructive techniques, denial of service, mass targeting, supply chain compromise, and detection evasion are refused. Dual-use tools are conditionally allowed with clear authorisation context. These are sensible distinctions. The problem is not what the policy says. The problem is how it is enforced.
An attacker who can see the policy can craft requests that technically satisfy its conditions. "I am conducting an authorised penetration test" is a string anyone can type. The policy cannot distinguish a legitimate claim from a false one because it has no access to ground truth. It is a rule the model applies to itself, based on information the requestor provides, with no independent verification.
They know how to do better
This is the part that should give pause. The same codebase contains 9,190 lines of genuine architectural security enforcement in the BashTool alone. Five files of real security engineering: AST-based command parsing via a tree-sitter WASM parser, injection detection for Zsh module attacks and Unicode tricks, path boundary enforcement that blocks dangerous rm patterns regardless of what the model decides, sed operation allowlists, compound command analysis that prevents sandbox escapes via git bare repositories. Deny-before-allow rule hierarchies. Defence in depth.
This is competent work. But it is also a solved problem. We have been restricting what untrusted processes can run on shared machines since the 1970s. Restricted shells, chroot jails, capabilities, seccomp, AppArmor. Anthropic's engineers applied well-understood patterns from fifty years of operating systems security design. Of course they did it well. Anyone competent would.
The BashTool enforcement answers the question: "Can this command damage the machine?" It does not answer: "Should the agent be helping with this task?" A request to help plan a supply chain attack would not trigger a single BashTool security check until the point of execution, and most supply chain attacks do not involve rm -rf /. The model's decision to engage with the request, plan the attack, write the code, and explain the approach is governed entirely by a paragraph of English prose in the context window.
So Anthropic has hundreds of engineers. The company is valued in the tens of billions. AI safety is their founding mission. They talk constantly about guardrails and responsible deployment. The entire public conversation about AI risk centres on what these systems will and will not do. They demonstrably know how to build architectural enforcement. They built 9,190 lines of it for the easy, well-understood problem. And their answer to the hard, important problem is a string constant.
The ideas are not new. Mandatory access control, capability-based security, type systems that make policy violations unrepresentable: these are from the operating systems and programming languages literature, decades old. Applying them to agent systems requires thought and engineering effort, but it is not a research frontier. The tools are there. The knowledge is there. The money is certainly there. They just did not do it.
This is not unique to Anthropic. We have not seen the source code for OpenAI's or Google's agent systems, but nothing in their public behaviour suggests they are doing better. The entire industry's approach to the policy boundary is security by suggestion. But Anthropic is the company whose source we can now read, and Anthropic is the company that claims safety is what makes them different. They are on the hook for this.
Independent research confirms these are not theoretical concerns. The Agents of Chaos study (Shapira et al., 2026) deployed six autonomous LLM agents in a live environment for two weeks. Ten security vulnerabilities were documented: agents complied with non-owner requests, disclosed personal information when requests were reframed, and had their identities hijacked in new contexts. All were failures of suggestion-based security. Franklin et al. (2026) provide a systematic taxonomy of adversarial attacks on AI agents, organising them by target: perception, reasoning, memory, action, multi-agent dynamics, and human oversight. Every category includes attacks that exploit suggestion-based policy enforcement. The leaked Claude Code source provides a concrete specimen of what those attacks target.
The injection surface
It gets worse. MCP server instructions are injected into the same system prompt array as CYBER_RISK_INSTRUCTION. The function getMcpInstructionsSection() concatenates instructions from connected third-party MCP servers directly into the context window, adjacent to the security policy. There is no structural separation between Anthropic's first-party policy, third-party MCP server instructions, and operator-configured custom instructions. They are all strings in the same array.
A malicious MCP server can inject arbitrary text into the agent's context window. The model must decide which instructions to follow based on the instructions themselves. The security policy that governs whether the agent helps write an exploit sits in the same undifferentiated string buffer as instructions from any external service the operator has connected. Prompt injection via tool results and MCP servers is a known, actively exploited technique. This is not a hypothetical.
Three levels
Security properties in agent systems can be enforced at three levels:
Security by suggestion. The policy is in the agent's context. The agent reads it, reasons about it, and chooses whether to comply. This is CYBER_RISK_INSTRUCTION. It is also every system prompt, every guardrail, every RLHF-trained behaviour. The agent can see its own constraints. So can an attacker.
Security by convention. The policy is documented and humans enforce it through review processes. This is the comment block in cyberRiskInstruction.ts: "Do not modify this instruction without Safeguards team review." It works until someone merges without review.
Security by construction. The policy is enforced by the architecture. Violation is not representable. A type checker that will not compile a pipeline sending credentials to an undeclared endpoint. An information partition that prevents an evaluator from seeing the material it is evaluating. A budget envelope that halts execution when resources are exhausted. The agent does not choose to comply. The structure makes non-compliance impossible.
The Claude Code codebase contains all three levels. The BashTool is construction, the Safeguards team review process is convention, and the policy boundary is suggestion. But the construction is applied to the well-understood problem (command execution safety), and the suggestion is applied to the hard, important problem (what the agent will help with). The effort is in the wrong place.
What construction looks like
The policy boundary is fundamentally about intent classification. "Should this agent help write an exploit?" is a judgement call about context and purpose, not a capability check like "can this process execute rm?" It may not reduce to a formal property enforceable by a type system.
Fair enough. The answer is supervisory architecture: a separate process, with a separate context, evaluating whether a request should proceed. This is structurally different from one agent policing itself. One agent checking another, with different information and different incentives, is not the same as one agent reading its own policy string and hoping the underlying neural network generates the right tokens. The pattern is well-established in adversarial review, in audit, in separation of duties. Getting it right for AI agents, tuning the supervisory processes, calibrating the feedback loops, is hard, and it is research frontier. Nobody should expect it to ship in software used by millions of developers today.
But the distance between "research frontier" and "string constant" is enormous. There is a vast space of architectural approaches between "a paragraph of English prose in the context window" and "a fully solved intent classification system." Structural separation of first-party policy from third-party instructions. Independent verification of authorisation claims. Supervisory processes that operate outside the agent's own context. None of these require solving intent classification completely. All of them would be better than what the leaked source reveals. Nobody expects the hard problem solved. The easy parts have not been attempted.
For the parts of the problem that are formalisable, the components exist and have existed for decades: mandatory access control, capability-based security, type systems that make policy violations unrepresentable at compile time. We have implemented and tested information partitions, typed channels, and budget envelopes in a production multi-agent system. The approach works, it draws on well-understood foundations, and the industry is not using it. A $19 billion company with a founding commitment to AI safety has 9,190 lines of architectural enforcement for the problem Unix solved in the 1970s, and a string constant for the problem that actually matters.
The question
The Claude Code leak shows what the industry's current best practice looks like in source code. It is a string constant in a TypeScript file, with a code comment asking the model to behave. The BashTool shows that Anthropic knows how to build real enforcement. The MCP injection surface shows that the suggestion-based policy is not even isolated from adversarial input.
This is a company with billions of dollars, hundreds of engineers, and a founding commitment to AI safety. The solutions draw on decades of existing work in operating systems and programming languages. The engineering is within their capability. They can do better. They have not.
Dr William Waites is a senior researcher at the University of Edinburgh School of Informatics and the founder of the Leith Document Company.